
Artificial Intelligence is evolving faster than ever, and nowhere is this more apparent than in the rapid advancements of Large Language Models (LLMs). Whether you’re building a knowledge assistant, an automated research analyst, or a coding helper, the backbone of your AI product is almost always an LLM.
But here’s the catch: not all LLMs are created equal — and “best” depends on what you value most. Is it accuracy? Cost-efficiency? Safety? Throughput speed?
At Almma.AI, the world’s first dedicated AI marketplace, we’ve developed a benchmarking framework that rigorously evaluates models across Quality, Safety, Cost, and Throughput — so both creators and buyers can make data-backed decisions before deploying their AI agents.
This post is your deep dive into how leading models perform, backed by three analytical views from AlmmaGPT’s evaluation engine:
- Model performance across key criteria (Quality, Safety, Cost, Throughput)
- Trade-off charts to reveal sweet spots between Quality, Safety, and Cost
- Per-scenario leaderboards to show strengths in reasoning, safety, math, coding, and more
By the end, you’ll know exactly how to choose the right model for your next AI build — especially if you plan on selling it on Almma.AI, where performance and trust translate directly into higher marketplace sales.
1. The Big Picture: Best Models by Overall Performance
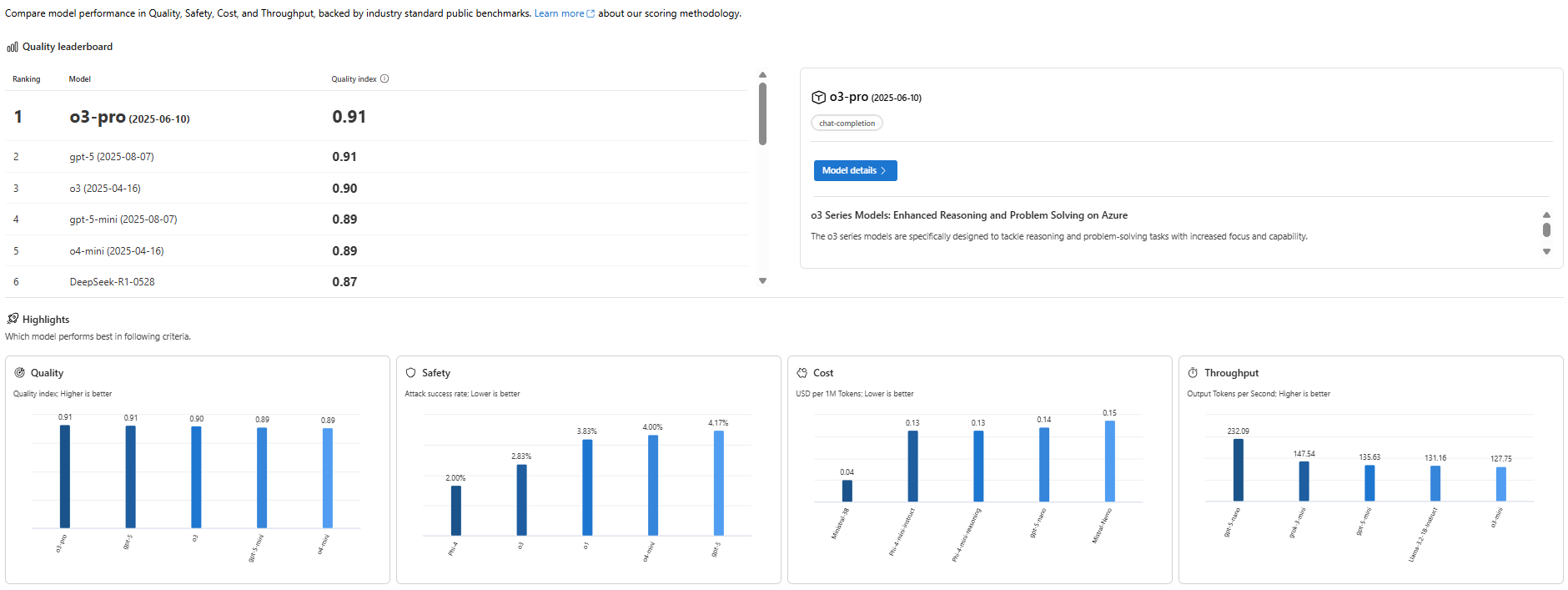
📊 Image: [AlmmaGPT’s best models by comparing performance across various criteria]
Before we get into the weeds, let’s start with the big picture: How do today’s leading LLMs stack up overall in quality?
When AlmmaGPT runs a quality index test, it blends multiple benchmark datasets covering reasoning, knowledge retrieval, math, and coding, creating a single, easy-to-read metric for performance.
The Quality Leaders
Our latest leaderboard shows:
| Rank | Model | Quality Index |
|---|---|---|
| 1 | o3-pro | 0.91 |
| 2 | gpt-5 | 0.91 |
| 3 | o3 | 0.90 |
| 4 | gpt-5-mini | 0.89 |
| 5 | o4-mini | 0.89 |
| 6 | DeepSeek-R1 | 0.87 |
Key takeaway: o3-pro and gpt-5 are essentially tied for the top spot, showing elite capability across the board — though how you prioritize cost and safety may change what’s “best” for your unique use case.
Drilling Down into Core Metrics
- Quality: o3-pro and gpt-5 set the bar with 0.91, followed closely by o3.
- Safety: Here’s where Phi-4 surprises most people — with a near unbeatable 2% attack success rate, it edges ahead of more famous names.
- Cost: Mistral-3B isn’t the most accurate, but at $0.04 per million tokens, it’s absurdly cheap for non-critical tasks.
- Throughput (Speed): gpt-4o-mini is the Formula 1 of LLMs at 232 tokens/sec — perfect for real-time use.
Match Models to Your Priorities
If your priority is:
- Enterprise-grade accuracy: o3-pro or gpt-5
- Maximum safety: Phi-4
- Budget efficiency: Mistral-3B
- Ultra-high responsiveness: gpt-4o-mini
Remember: In an AI marketplace like Almma.AI, your choice impacts user satisfaction and cost of operation, both of which directly affect profitability.
2. Navigating Trade-Offs: Quality vs Cost vs Safety
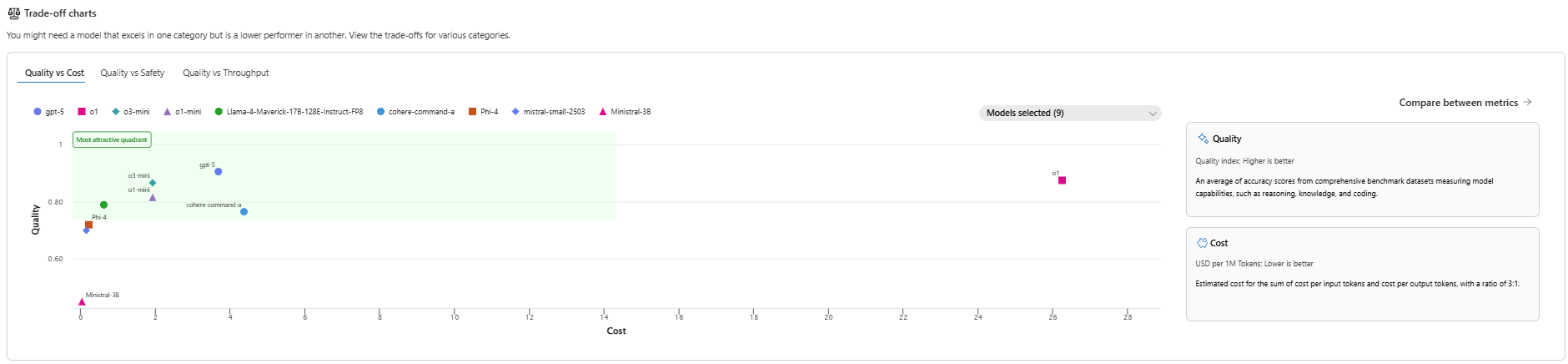 📊 Image: [AlmmaGPT Trade-off Charts]
📊 Image: [AlmmaGPT Trade-off Charts]
One of the biggest mistakes AI builders make? Picking the most famous or most expensive model and assuming it’s “best.”
The reality: AI is about trade-offs. You might choose:
- A model that’s slightly less accurate but 10x cheaper
- A super-fast model that’s not the safest for sensitive prompts
- A safe, high-quality model that’s slower but perfect for compliance-heavy industries
Our Quality vs Cost trade-off chart puts these decisions into perspective.
The Sweet Spot Quadrant
In AlmmaGPT’s visual, the upper-left quadrant is the most attractive: high quality, low cost.
Here we find:
- o3-mini and o1-mini — Balanced performance with wallet-friendly pricing.
- gpt-5 — More expensive than the minis, but offers cutting-edge accuracy.
High-End Luxury Picks
o1 shines at extreme accuracy (~0.92 quality) but at a huge $26 per million tokens. Great for premium, mission-critical deployments, but overkill for simpler agents.
Budget Workhorses
- Mistral-3B — Bottom line pricing, good enough quality for text generation that doesn’t need deep reasoning.
- Phi-4 — Great combination of affordability and safety, perfect for compliance-heavy sectors on a budget.
Pro Tip for Almma.AI Creators: In a marketplace where your profit margins depend on the balance between operational cost and customer satisfaction, models in the sweet spot quadrant (o3-mini, phi-4, gpt-5) often yield the best lifetime ROI.
3. The Scenario Deep-Dive: Leaderboard by Skill Domain
 📊 Image: [AlmmaGPT Leaderboard by Scenarios]
📊 Image: [AlmmaGPT Leaderboard by Scenarios]
Overall rankings are great, but the truth is: 🚀 Different models excel in different specialties.
That’s why AlmmaGPT’s Scenario Leaderboards break performance down into specific skill areas — giving you fine-grained insights to match LLM choice with your agent’s purpose.
3.1 Safety-Driven Benchmarks
Safety is measured via attack success rates in prompt injection and misuse scenarios — the lower the number, the safer it is.
- Standard Harmful Behavior: o3-mini, o1-mini, and phi-4 scored a perfect 0%.
- Contextually Harmful Behavior: o3-mini at just 6% is far safer than gpt-4o at 12%.
- Copyright Violations: Nearly all top performers sit at 0% — good news for IP integrity.
When to prioritize: Agents in finance, law, health, education — anywhere trust and regulation matter.
3.2 Reasoning, Knowledge, and Math
- Reasoning: Five models tie at 0.92, including gpt-4o, o3, and o3-pro.
- Math: gpt-4o and gpt-4o-mini lead with 0.98 — perfect for data-heavy applications.
- General Knowledge: gpt-5, gpt-4o, and o3-pro score a strong 0.88.
When to prioritize: Agents for research, diagnostics, analytics, and technical problem-solving.
3.3 Coding Capability
- The top score is modest at 0.77 (gpt-4o), showing code generation is improving, but still a niche challenge.
When to prioritize: Development productivity tools, debugging assistants.
3.4 Content Safety & Truthfulness
- Toxicity Detection: Leaders: o3 and o3-mini with 0.89 — useful for moderation.
- Groundedness: gpt-4o leads at 0.90 — great for factual, evidence-backed outputs.
3.5 Embeddings & Search
These benchmarks test how well LLMs handle semantic similarity, clustering, and retrieval — crucial for AI agents building knowledge bases.
- Information Retrieval: Best is 0.75 — still evolving.
- Summarization: Peaks at 0.32.
When to prioritize: Search bots, knowledge agents, RAG (Retrieval-Augmented Generation) systems.
4. Choosing an AI Marketplace Environment
Deploying an agent publicly, especially on Almma.AI, means thinking like both a builder and a business owner. Here’s why these benchmarks are marketplace gold:
4.1 Customer Experience
Better quality models = happier users = higher repeat usage.
For public-facing agents, gpt-5 or o3-pro could lead to higher marketplace ratings and reviews.
4.2 Operating Costs
Highly accurate models are expensive to run 24/7.
If your agent serves thousands daily, a “sweet spot” model like o3-mini keeps margins healthy.
4.3 Risk Management
Agents that generate unsafe or false outputs risk takedown or negative publicity.
Safety-first models like phi-4 protect your brand and marketplace standing.
4.4 Niche Domination
In Almma.AI’s fast-growing ecosystem, you can win by targeting niche capabilities.
For example:
- Financial modeling? gpt-4o-mini for advanced math.
- Research assistant? o3-pro for reasoning depth.
- Education tutor? Safety + knowledge = phi-4 or o3-mini.
5. Recommendations by Use Case
Here’s your quick decision matrix, based on our analysis:
| Use Case Type | Best Model | Why |
|---|---|---|
| General-purpose assistant | gpt-5 | Balanced high quality and versatility |
| High-volume chatbot | o3-mini | Good quality at low cost, safe enough for the public |
| Math-heavy agent | gpt-4o-mini | Top in math accuracy, high throughput |
| Educational tutor | phi-4 | Excellent safety record, low cost |
| Document search & RAG | o3-pro | Strong reasoning + retrieval embedding capabilities |
| Content moderation bot | o3 / o3-mini | High toxicity detection accuracy |
| Developer co-pilot | gpt-4o | Leading in coding and general knowledge |
6. The Almma.AI Advantage
While you can read about benchmarks anywhere, Almma.AI’s unique edge is that we integrate these live performance analytics into the marketplace itself.
That means:
- Buyers choosing an AI agent can see its underlying model’s strengths.
- Creators can experiment with different LLM backends inside AlmmaGPT before listing.
- The marketplace rewards agents that consistently deliver, which is better for the ecosystem as a whole.
Closing Thoughts
AI model selection is about alignment with your goals, not just picking “the best” model on paper.
If you’re building for profitability on Almma.AI, you need to think like this:
- Use data (like these charts) to weigh quality vs cost vs safety.
- Pick scenario strengths that match your agent’s function.
- Optimize continuously — swap models if usage patterns change.
By grounding your choice in evidence-driven comparisons, you give your AI the best shot at marketplace success — and contribute to a safer, more reliable AI ecosystem for everyone.
💡 Next Step: Ready to build, test, and sell your own AI agent?
Sign up as a creator on Almma.AI, run your ideas through AlmmaGPT’s model selection tools, and list your AI where buyers are actively looking for the next breakthrough.
Leave a Reply